Г Р А Ф И Т — б а з и с
Приложение 2.
Элементы
языкового обеспечения визуализации деятельности
В приложении кратко описаны искусственные языки представления знаний, применяемые для описания систем различного рода. Данные описания не претендуют на языковые стандарты, в частности поэтому языковые правила в большинстве своем сформулированы нестрого; тем не менее они отражают реалии применения соответствующих языков и после усвоения могут составить основу инструментария представления профессиональных знаний.
Приложение предназначено для обучения работе с языками.
К сему прилагается | Вспомогательные языки визуализации | Декларативные
Здесь даются определения для языков, используемых как вспомогательные в формализации. Языки, выделенные как основные, определяются (и рассматриваются) в основном тексте.
Содержание
Текстовые деклар-языки (ТДЯ)
Описывает объекты деятельности (в информодели — величины задачи, подзадачи) в форме, приближенной к текстовым языкам программирования, в т.ч. включает объявления величин алгоритма. Различные стандарты языка называют также автокодами, псевдокодами.
Вообще говоря, ТДЯ, рассматриваемый сам по себе, м.б. только ментал-языком (независимо от информатизованности), либо частью инфор-языка. Полный инфор-язык по определению включает все частные языки и объединяющий их ген-язык.
В России более-менее употребителен целый ряд ТАЯ. Исходя из эргономики представления, можно выделить следующие:
как «родной» - язык словаря данных МФЗ-ДПД, описанный, напр., в книге Г.Н. Калянова «CASE. Структурный системный анализ», Гл. 3;
как иноязычный (исходно) — ЯМД-субязык инфор-языка SQL, определённый в литературе по данному языку.
ЯСД сравнительно прост и рассчитан на применение совместно с описаниями структур сущностей.
ЯМД-SQL полностью определяет сущности как объекты данных, напр., записи БД.
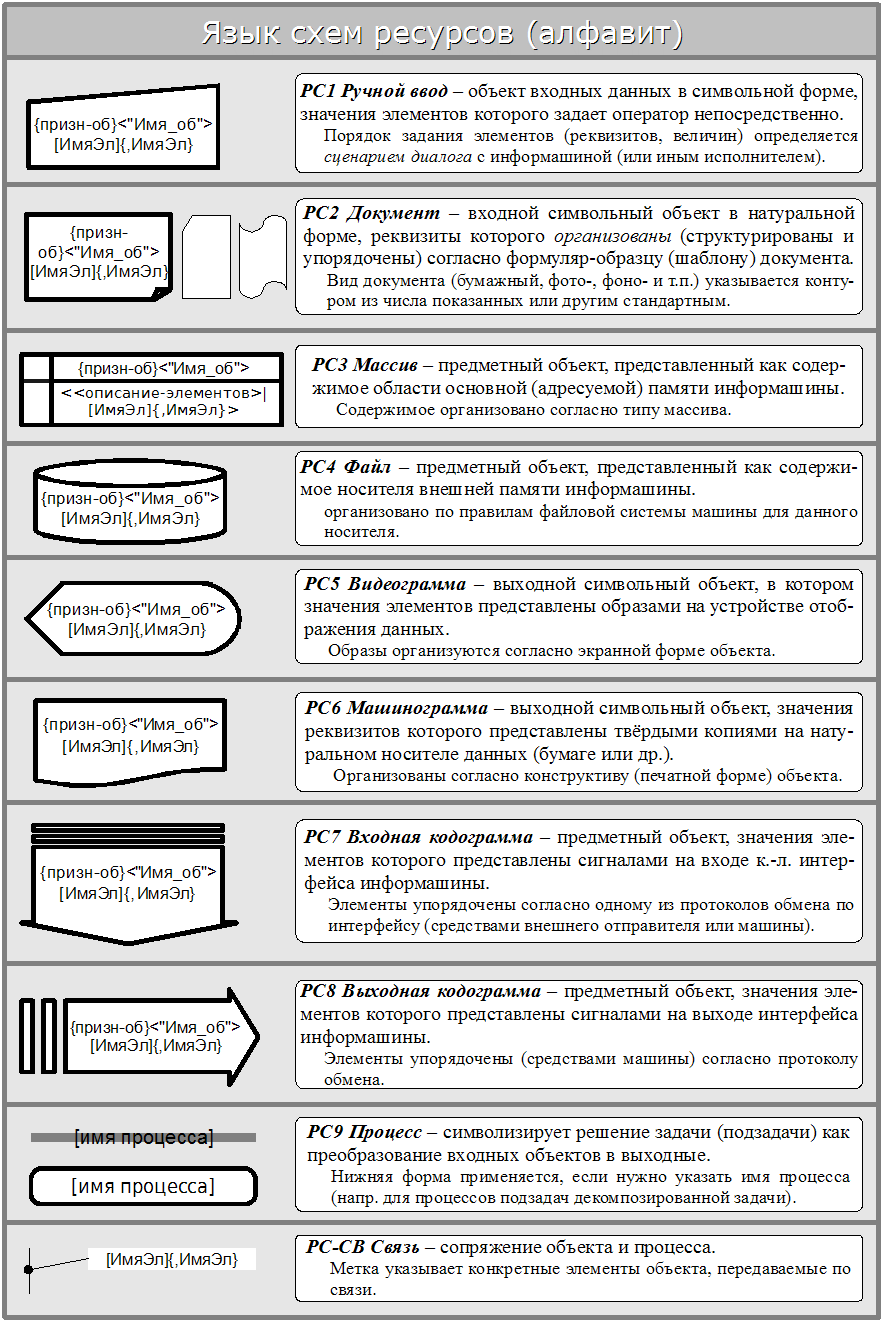
Язык схем ресурсов
Служит для графического описания состава и взаимосвязи ресурсов (объектов вещества, энергии, данных) конкретной задачи, в т.ч. решаемой с применением информатических машин (систем, комплексов, сетей).
Алфавит языка
Алфавит образуют символы, перечисленные в таблице ниже:
Правила языка
5.3.2.1. Схемы данных представляют собой орграфы, причём рёбрами являются линии связи, а все остальные символы языка трактуются как вершины различных типов. Направление на схеме специально не указывается, т.к. соответствует привычному направлению чтения.
Схемы составляются по следующим основным правилам.
схема образуется из объектов и процессов, причём объекты связаны только через процессы;
схема состоит по крайней мере из одного процесса, одного входного и одного выходного объектов данных (конкретный состав объектов определяется содержанием процесса);
среди входных объектов выделяются те, которые содержат условно-постоянные данные;
основные признаки объектов: стабильности элементов (указание для данных – слово «Справочник»); природы данных (для отчуждённых знаний, напр. – слово 'Знания'); сочинитель может вводить и иные признаки, описав их как дополнительные правила языка;
объект Массив употребляется только когда его данные содержатся внутри одной машины (системы с общим полем ОП) и только если предполагается, что другие задачи (источники/потребители этих данных) всегда выполняются в течение одного сеанса с данной задачей.
Имя объекта (метка) на реальной схеме указывает его тип; метки д. б. краткими, уникальными для всей совокупности задач описываемой системы (напр. организации, использующей язык). Для наглядности метку рекомендуется производить от полного имени объекта (документа, сообщения) по общеязыковым правилам (см. Разд.1 Прил.7, а также здесь).
в задаче могут использоваться разные формы одного объекта. Тогда на схеме помещают одинаково именованные обозначения этого объекта;
список ИмяЭл применяется, когда нужно указать на использование в процессе части содержимого составного объекта (напр., конкретных реквизитов документа);
для первоначальной схемы, когда точно неизвестно, к какому виду отнести объект, можно обозначить его как наиболее часто встречающийся (первый в подгруппе);
схема данных м.б. укрупнённой (задача отображается как единое целое, т.е. одним блоком «Процесс») или детальной;
на детальной схеме выделяются подпроцессы по этапам преобразований ресурсов (на схеме появляется несколько уровней линий процессов, связанных через объекты промежуточных данных) и/или по независимым друг от друга функциям задачи/этапа (на одном уровне размещается несколько линий с разрывами, т.е. линия процесса как бы разомкнута на отрезки). Каждая линия помечается именем соответствующего подпроцесса (функции).
Основным типом компоновки схем является вертикальная, при которой:
схема в целом строится и читается сверху вниз; символы процессов ориентированы горизонтально, а связи, соответственно – вертикально;
символы входных объектов располагаются в ряд над символом «своего» процесса, а символы выходных – также в ряд под ним.
Для удобства размещения в заданном формате допускается горизонтальная компоновка схемы, при этом она строится и читается справа налево, т.е. символы объектов расположены по столбцам, символы процессов ориентированы вертикально, а связи – горизонтально.
5.3.2.2. Язык исходит из классификации объектов данных задачи по ряду оснований, прежде всего по роли в процессе (входные/выходные/промежуточные, что отражается в компоновке схемы), далее по форме представления (символьная/предметная, отражается видом) и источнику поступления/выдачи (отражается разными типами объектов); далее по степени стабильности значений их элементов (отражается признаком и группировкой входных объектов).
Для структурирования дополнительно применяются элементы КогниСтиль (прежде всего скобки и/или ограничители).
Язык атрибуции данных
Служит для описания свойств объектов данных (элементарных, сложных) с т. зр. формального исполнителя (напр. информашины) в текстово-табличной форме. Употребляется, как правило, совместно с языком схем данных.
Алфавит языка
Алфавит образуют значения атрибутов данных. Идентификаторы атрибутов и значений перечислены в таблице ниже:
|
Значение (имя) |
Характеристика |
Примечания |
|
Основные атрибуты |
||
|
Имя элемента |
||
|
<текст-имени> |
Представляет естественное имя для человека; даётся по правилам родного языка |
|
|
Метка элемента |
||
|
'Имя_элемента' |
Представляет формальное имя для моделей (формул, алгоритмов, схем); дается по общеязыковым правилам |
(см. п/р 1.1 Прил. 7) |
|
Система кодирования (показателя составного реквизита) |
||
|
'Текст'['('<'Имя_яз'>')'] |
Указывает на запись данных в алфавите некоего языка; 'Имя_яз' – краткое наименование языка: «рус», «матем.» и т. п. В машинном представлении знакам алфавита соответствуют коды заданной разрядности; возможны разные кодировки одного алфавита. |
При наличии вариантов кодировки указать нужный |
|
<N->'ичная' |
Указывает систему счисления числовых данных; <N-> – корень названия СС: десятичная, 16-ричная и т. д. |
|
|
<'Форм.'|'Слов.'> |
Указывает способ кодирования данных-величин той или иной формальной логики (напр. булевой): формальный – знаками (кодами) некоего математического алфавита по числу возможных значений величины, словесный – словами некоего естественного или искусственного (напр. машинного) языка. |
Возможные коды булевых величин: формальный – цифрами 0/1; словесный русский – да/нет; машинный – избранными значениями байта, машслова. |
|
Тип данных (показателя составного реквизита) |
||
|
'Симв.' |
Обозначает символьный тип (данные рассматриваются как строки знаков или кодов в некоей кодировке) |
Кодируется как текст |
|
'Числ.' |
Обозначает числовой тип (данные рассматриваются как числа в некоторой системе счисления) |
Кодируется как число |
|
'Логич.' |
Обозначает логический тип (данные рассматриваются как значения величин некоторой логики) |
Обычно – булевой |
|
'Дата' |
Для данных времени в специальном формате (напр. машинной базы данных, динатаба) |
Длина поля фиксирована |
|
'Прим.' |
Для данных типа Примечание (машинных текстов для человека, не обрабатываемых автоматически) |
Только в некоторых СУБД |
|
Длина показателя |
||
|
m['/'n] |
Числовой код, где: m – предельная длина строки символов, словесного кода логич. величины или целой части числа; n – длина дробной части (только для числа) |
При переменной длине показателя |
|
Ключ сортировки |
||
|
<k> |
Числовой код k=1,2,...N, определяемый для реквизита объекта (составного – некоторых или всех); значения указывают очередность алгоритмического упорядочения массива объектов: сначала по реквизитам с ключом 1, потом по 2 и т.д. |
Для массивов объектов, подлежащих сортировке |
|
Дополнительные атрибуты |
||
|
Способ ввода (получения значения реквизита) |
||
|
'Свободный' |
Адресант задачи (обычно человек-оператор) указывает любое значение допустимого типа (может не проверяться адресатом). |
|
|
'Выбор' |
Указывает, что человеку предлагается список значений для ввода; он выбирает одно значение. |
|
|
'Программный' |
Указывает, что значение получается как результат обработки по некоторому алгоритму, входящему в решение данной задачи. |
|
|
Метод контроля |
||
|
'Совпадение' |
Указывает, что адресатом задачи (напр. машиной) принимается допустимое значение реквизита (единственное или одно из возможных). |
|
|
'«Вилка»' |
Указывает, что значение (числовое) проверяется адресатом на соответствие некоторому диапазону; ввод, не попадающий в диапазон, отвергается с выдачей сообщения адресанту. |
|
|
'Логический' |
Указывает, что адресатом проверяется, выполнено ли некоторое соотношение результатов ввода с другими величинами (в частности, соответствие заданному типу данных). |
|
|
Параметры контроля |
||
|
{определение-i} |
перечисляются значения-уставки и/или логические условия (правила) для i-того контролируемого реквизита. |
|
|
|
|
|
Атрибуция данных проводится по следующим правилам.
А. Организация состава объекта м.б. описана одним из двух способов:
формальным – посредством структурной схемы объекта, показывающей отношения его элементов (напр. в виде классификационной диаграммы);
конструктивным – посредством конструктива объекта; показывающего конфигурацию и вид элементов (напр. в виде шаблона документа, чертежа предмета).
На практике можно сочетать оба способа.
В частном случае объект может состоять из единственного элемента.
В общем случае описываемый элемент объекта (напр., реквизит документа) является составным, т.е. включает основание (постоянную часть, определяющую значение всего реквизита) и показатель (значение, возможно, переменное); показателей м.б. несколько, напр. значение величины и обозначение единицы измерения значения.
Основанием составного реквизита служит его имя; оно же указывается и в конструктиве объекта данных (натуральном бланке, экранной/печатной форме).
Б. Основные атрибуты конкретного объекта (элемента составного объекта) организуются в виде записи. Для каждого атрибута выбирается одно из возможных значений. Записи об элементах объекта сводятся в таблицу вида:
|
Имя реквизита |
Метка |
Тип данных |
Система |
Длина
|
Ключ сортировки |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В. Дополнительные атрибуты вводятся (выборочно) для реквизитов, значения которых получаются извне задачи (скажем, заполняются оператором при машинном решении) и определяют способы и критерии контроля правильности значений. Эти атрибуты также организуются в виде записей об элементах объекта, сводимых в таблицу вида:
|
Метка |
Способ ввода |
Метод контроля |
Параметры контроля |
|
|
|
|
|
|
|
|
|
|
Атрибут Метка указывает на принадлежность дополнительных атрибутов объекту, который имеет ту же метку в основной таблице. Для любого другого атрибута допускается одно и более из возможных значений (что означает множественность ввода и/или контроля).
Г. Допустима общая характеристика для группы полей (класса реквизитов) одной строкой (под обобщённым именем реквизита).
В начало страницы | Оглавление | Версия для печати
Copyright © Жаринов В.Н.