Концепция | Генеральное структурирование отчуждаемых знаний
Как можно структурировать весь состав форм представления знаний? Для этого следует включить обобщённую составляющую; возможная классификация показана на схеме ниже.
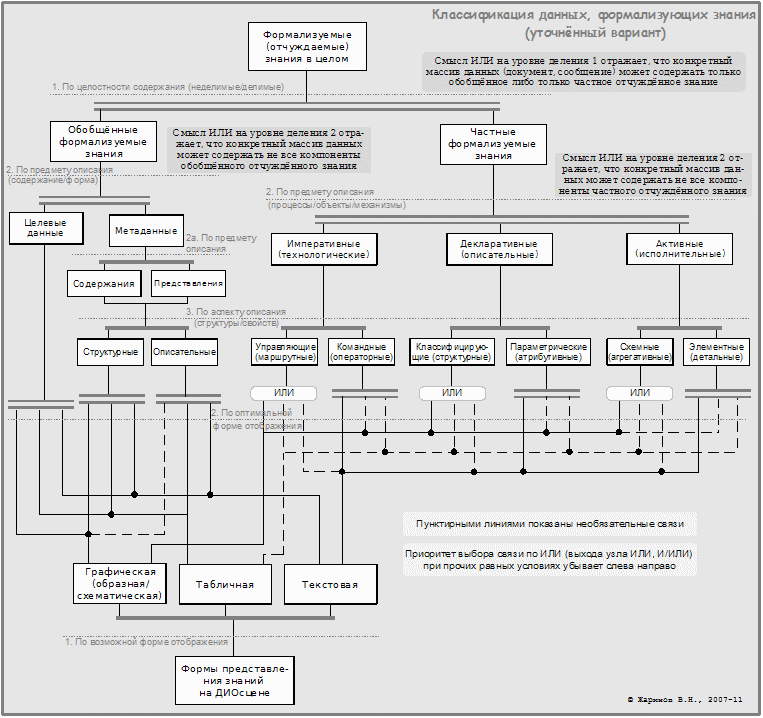
Генеральная классификация отчуждаемого знания (формализуемых данных)
При составлении схемы использованы общеструктурные обозначения графит-метода, вводимые в п/п 1.3.1.4 Приложения 2. Именно этот метод (вкратце обсуждённый в п/п 1.4.3.2) служит развитием идей когнитивной эргономики для представления формализуемых данных в целом, исходя из рассмотренной классификации.
Видно, что обобщённое знание трактуется, во-первых, как целостное (и именно поэтому неделимое по аспектам описания), и во-вторых, как полиформальное (может представляться и текстом, и таблицами, и графикой). По сути, к результатам его отчуждения относятся любые массивы данных (документы, сообщения) – и в частности, художественные произведения. Мы также видим, что классификации обобщённого и частного знаний лишь до некоторой степени соизмеримы – целевые данные не классифицированы полностью (что вытекает из их природы, как мы её определили выше).
Форма представления (записи) знания этого рода м.б. информатизована (на чём основана возможность подготовки инфордоков); однако для содержания это не обязательно так. Неинформатизованность содержания (полная или частичная) обусловливает невозможность вполне разделить его на частные виды знания. Требование же информатизации удовлетворяется тем, что определяются метаданные («данные о данных») применительно как к форме, так и к содержанию определяемых данных (будем называть их целевыми). Естественно, что при этом привлекаются науки о языках – естественных и искусственных. И чтобы привлекать языковые знания – надо их иметь для начала.
Для широкого круга субъектов моделирования и формализации (т.е. вообще-то обычных людей, желающих – или вставших перед необходимостью – «правилу следовать упорно – чтоб словам было тесно, а мыслям – просторно» :)) это в первую очередь знание родного языка и хотя бы ещё одного – исходя из сказанного в п. 1.4.1 о роли языка на качественной стадии формализации. В идеале должен изучаться один естественный язык из каждого типа, выделяемого в лингвистике (по т.н. парадигме грамматики, иначе говоря, строю) – агглютинативного, флективного, аналитического, изолирующего1. Промежуточное решение – изучать только язык из строя, принципиально не совпадающего со строем родного языка учащегося; практически для носителей неизолирующих языков это будет язык изолирующий (напр., китайский).
Содержательные метаданные удобно рассматривать по родам информационных процессов в смысле Фридланда (познание, управление, обучение)2 и категориям культуры (искусство, наука, вера). В науке такими метаданными служат, напр., правила получения/оценки опытных данных, отнесения их к научно достоверным (или напротив, к фактам художественного вымысла и/или веры). В значительной степени это составляет предмет, скажем, теорий измерения и эксперимента (и вообще моделирования); однако более общие правила (различающие и рода процессов, и категории культуры) относятся уже к источниковедению.
Если подумать, чем определяется построение метаправил вообще, то это предмет эпистемологии (теории познания) – ну и философии (которая, как уже говорилось, в последнее время взялась за рассмотрение информации).
С формальными метаданными всё проще – это правила оформления содержания (по структуре и свойствам представления); эти правила используются для чтения данных.
Качественно эти правила закреплены, допустим, в стандартах на документацию; в то же время существует свод правил неформализованных, составляющих «здравый смысл» в обращении с данными. Многие правила м.б. нестроги, что отражает принципиальную неопределённость «максимально широкой предметной области» знания – стремиться же к полной определённости – значит, говоря словами С. Лема, строить «Общую Теорию Всего» :)
Математически обычно используются метаязыки типа РБНФ; при этом их алфавитными знаками (лексемами) при полиформности д.б. как текстовые, так и графические (табличные) символы. То же относится к самим РБНФ-знакам; исходя из этого, в Приложении 2 был введён графит-диалект РБНФ-метаязыка. Здесь уже надо формализовывать и «здравый смысл» (хотя это обычно делается не до конца в силу вышесказанного) – но если выделить ограниченную (во многом опять же исходя из здравого смысла, только уже больше эпистемологического) предметную область, то применительно к ней можно добиться полной и целостной формализации. Общие принципы устанавливает теория формальных языков (и вообще математическая лингвистика)3.
Информатическая формализация метаданных исходит, разумеется, из результатов математической; при этом строится модель массива данных, а скорее – некоторого класса массивов.
Очевидно, наиболее общей будет классификация по формам представления – отсюда текстовые, табличные, графические модели (и средства работы с ними). Кроме того, следует ввести смешанную категорию – модели комплексного документа (сообщения). Наконец, не лишней будет обобщающая категория – модели составного массива (из массивов любых из названных категорий). Сама модель формализует частное знание.
В общем такая модель задаёт информатизованный документ (инфордок) в определении из п. 1.1.2 Приложения 1. Общие правила устанавливаются в информатике, а их применение протекает как процесс информатизации в узком смысле (см. Б) в определении из п. 1.1.2 Приложения 1).
Частное знание делимо в силу принципиальной информатизуемости содержания (формализуемости вплоть до командного уровня).
Частное знание показано как вполне закономерно представляемое в тех или иных формах. Конечно, это определяется соображениями когнитивной эргономики; исходя, в частности, из рекомендаций создателя техноязыка, мы вводим приоритет представления структурной составляющей любого вида частного знания в графической форме (трактуемой здесь прежде всего как схематическая).
Для инфордока, разумеется, д.б. информатически формально заданы все языки его записи (и алгоритмически строго определены процессы их применения для реализации).
Целостно частное знание выражается информатически формально на языках программирования. Представляется интересным определить и для них круг изучения. Однако здесь мы сталкиваемся с многоообразием парадигм программирования (не говоря уже о языках).
И в этом случае имеет смысл применить подразделение по видам частного знания; тогда получим три элементарных вида строёв прогязыка, формулирующих предметную область (задачу) в различных терминах, а именно:
императивный – ЧТО делать для достижения цели; модель есть схема действий, возможных в рамках области, задачи (сюда можно отнести, скажем, процедурные и объектные прогязыки);
декларативный – КАК достичь цели; модель строится как схема отношений области, задачи (естественно отнести сюда логические инфор-языки);
активный – ЧЕМ достигается цель; строится модель тракта исполнителя как схема преобразований (сюда можно отнести, скажем, функциональные и продукционные).
При этом следует помнить: «родным» для массовых искусственных исполнителей является язык императивного строя. Именно такой и нужно изучать в любом случае.
Представляется верным согласиться с т. зр. ИТ-специалистов, ратующих за минимальный и расширяемый наиболее естественным и предсказуемым образом прогязык, практически проверенный в промышленности; в частности, следуя позиции И. Ермакова (см. ч. 5 его доклада), это м.б. языки семейства Оберон.
Вообще говоря, роль информатики в формализации системно определялась ранее, в частности, Перегудовым. В настоящее время для определения роли математики, информатики и языковых наук в формализации (и вообще в жизни и деятельности) выдвигаются различные концепции; прежде всего можно назвать отечественную «Математика-Информатика-Языки» (МИЯ), последовательно излагаемую в рамках веб-ресурса Информатика-21.
Отметим, что одна из форм представления выбирается в конкретном массиве как ведущая; т.о. можно и нужно говорить о документе, сообщении (и прежде всего информатизованном) как о:
текстобазированном – где структура задана текстоэлементами (цепочками литер), в которые включены таблицы и/или изображения (если таковые имеются);
табулобазированном – где структура задана табличными ячейками, содержанием которых являются текстоэлементы и/или изображения (и/или, возможно, другие таблицы);
графбазированном – где структура задана изображениями (в первую очередь граф-схемами).
Кроме того, табличная форма может рассматриваться в структурном аспекте и как структуризация текста, и как вырожденный плоский граф, где рёбра сведены к смежности сторон ячеек-вершин.
Различные виды базировки отчасти закреплены стандартами на натуральные документы (анкета, трафарет, схема, таблица). Можно также найти примеры из информатизации, такие, как:
текстобазированные – гипертекст; «текст как интерфейс»;
табулобазированные – динамическая (распространяющая, жарг. «электронная») таблица;
графбазированные – документ-схемокурс (исходящий из концепции схематизации Г.А. Гуленкова); РДП-документ (вводимый по определениям в п/р 1.1 Приложения 2).
Конкретный тип базировки д.б. задан для инфордока в целом (независимо от его содержания).
Важно понимать, что если отказаться от «принципа абсолютизации диоформы» (в частных случаях – «абсолютизации текста», «абсолютизации картинки» – см. п. 5.2.2), то нужно рассматривать разно-базированные формы одного документа как изоморфные друг другу. Соответственно д.б. реализованы способы получения этих форм на одном и том же содержании; конечно, с сохранением смысла и без существенной потери когнитивного качества это возможно для вполне соотносимых друг с другом концепций представления.
Отдельно взятый документ (сообщение) может содержать только отдельные виды (компоненты) отчуждённого частного знания и тогда как результат (продукт) информатической стадии формализации является частичным по содержанию. Также он может содержать только отчуждённое обобщённое знание. Для выражения этого использованы узлы И/ИЛИ. Внутри же компоненты д.б. и структурная, и элементная части (что выражено узлами И).
В верхней подклассификации ИЛИ применимо безусловно только к отдельному массиву данных; для правильного его использования необходимы как минимум метаданные, а также базовые обобщённые знания. Однако они м.б. формализованными (в других документах, сообщениях) лишь частично (в остальном составляя «здравый смысл»); тогда ИЛИ также применимо, но условно (при наличии этого здравого смысла у адресата массива).
При наличии всех частных компонент (а также обобщённого знания в необходимой части) можно говорить, что документ даёт комплексное информатизованное описание (информодель) рассматриваемого вопроса (задачи); разумеется, нужны ещё целостность и адекватность описания, чтобы говорить о его качестве.
Вопросы качества литературного произведения рассматривали различные учёные и специалисты; можно отметить В.А. Каверина, который, будучи популярным писателем (кстати, и на темы науки), в то же время по первому образованию языковед4. Представляют определённый интерес и публикации, содержащие критику литературоведения (конечно, чтобы извлекать из них рациональные зёрна, нужно уже понимать суть этой дисциплины)5. И конечно, не следует пренебрегать работами о смысле массивов данных как продукте целенаправленной деятельности по синтезу данных (документов, сообщений) и по их организации в пространстве-времени-формах6. Базовые критерии можно перенести и на нехудожественные документы (сообщения)7.
Разработка документа с учётом оценки смысла показана для классификации здесь.
Можно сказать, что мы определили данные как предмет информатики. При этом классификацию можно применять не только к данным, представляющим отчуждённое знание (т.е. к идущим от субъекта моделирования/формализации), но и к воспринимаемым данным.
В начало страницы | Оглавление | Версия для печати
Copyright © Жаринов В.Н.
1 Популярное введение в естественно-языковые строи см. Девятов А., Мартиросьян М. – С.345-347. Интересный подход к информатизации соотношения между строями (а заодно и к обучению языкам и вообще к процессу обучения) можно найти в статье: Милашевич В.В. Дорога к многоязычию. // Химия и жизнь, №4/1981 – С.74-80.
Классификацию языков см.: Фридланд А.Я., 2005. – п. 2.5.
2 См. Фридланд А.Я., 2005. – п.5.1.
3 Популярно ряд вопросов математической лингвистики освещается, напр., в книге: Журавлёв А.П. Диалог с компьютером. – М.: Молодая гвардия, 1987.
О теории формальных языков см. в: Свердлов С.З., Питер, 2007. – Гл. Теоретические основы трансляции (с. 206-298); а также книгу: Мозговой М.В. Алгоритмы, языки, автоматы, компиляторы. – СПб.: Наука и техника, 2006.
4 В частности, см. формулировки критериев качества (на примере жанра НФ-романа) в этом интервью: Каверин В.А. Чтобы остаться...//в кн.: Письменный стол. – М.: Советский писатель, 1985.
5 Можно ознакомиться со статьёй: Лукин Е. Враньё, ведущее к правде. // ЕСЛИ, №11/2005.
6 Классическое определение смысла можно найти в: Фурдуев В.В. Стереофония и многоканальные звуковые системы. – М.: Энергия, 1973. – п.19 (с. 93-95). Современная и достаточно популярная работа на эту тему: Почепцов Г.Г. Информационно-политические технологии. – М.: Центр, 2003.
Вопросы практического источниковедения (наряду с добыванием данных) популярно освещены, напр., в книгах: Ющук Е. Интернет-разведка. Руководство к действию.–– М.: Вершина, 2007; Хант Ч., Зартарян В. Разведка на службе вашего бизнеса. – Киев: Укрзакордонвизасервис, 1992.
Переработка данных (как интеллектуальный процесс) рассмотрена (под названием «аналитико-синтетическая обработка») в работе: Герасименко В.А. Защита информации в АСОД. – М.: Энергоатомиздат, 1994. – Гл. 12.
7 Примеры оценки качества научно-технического документа см. в: Фёдоров Ю.Н., ИНФРА-Инженерия, 2008. – С. 34-50; Фёдоров Ю.Н., ИНФРА-Инженерия, 2011. – Введение.